
Performance and cost are important considerations when designing and implementing machine learning (ML) systems at scale. The speed and efficiency with which you can train your ML models and extract the maximum value from your data will determine the overall success of your project.
Data loading is one of the biggest performance factors in the ML process. For the best possible accuracy, you need to train your model with as much historical data as possible, and keep it up to date by retraining with fresh data as it arrives. This requires an ever-increasing amount of storage.
Traditionally, ML developers have had to make tradeoffs for this scalability — usually performance — by using higher latency but more affordable object storage APIs or writing systems that swap data in and out of object storage to faster local storage for processing. While PyTorch includes mechanisms for these, they are still a compromise performance-wise.
To address this, cunoFS has implemented PyTorch-specific optimizations for loading data, providing a no-compromise solution for PyTorch ML systems that require scalable, performant storage.
What is cunoFS?
cunoFS is a scalable, high-performance POSIX compatibility layer that lets you interact with object storage as if it were a native filesystem. Unlike FUSE-based solutions such as s3fs, it is highly performant ( up to 25x faster than using the native AWS S3 CLI), and is compatible with AWS S3, Azure Blob Storage, Google Cloud Storage, and other S3-compatible object stores, allowing you to run your existing apps using object storage as a filesystem
For ML use cases, this is advantageous: you can move your ML workloads to object storage without having to re-write your code to implement vendor-specific object storage APIs. This results in readily scalable storage and lower costs, without having to worry about performance or shuffling data between local and object storage.
Introducing the cunoFS ML optimizations for PyTorch
cunoFS was designed to make object storage usable for more use cases, and as part of our solution we’ve made S3 access via cunoFS incredibly performant. While building the core of cunoFS we recognized that we could optimize it further for specific applications — in this case, machine learning using Python and PyTorch.
The cunoFS ML optimizations overcome the latency limitations of object storage to greatly improve the performance of data loading. It does this by interacting with PyTorch and for each (randomised) Epoch providing accurate predictions on any upcoming data reads that cunoFS can prefetch in parallel. This high-performance data loader does not require any modification of your Python code: there’s no Python library to import or any change needed to your existing applications; you just enable the optimizations in cunoFS and run your ML workloads as usual.
Start using cunoFS today
Proven performance improvements for machine learning in Python — up to 13x faster
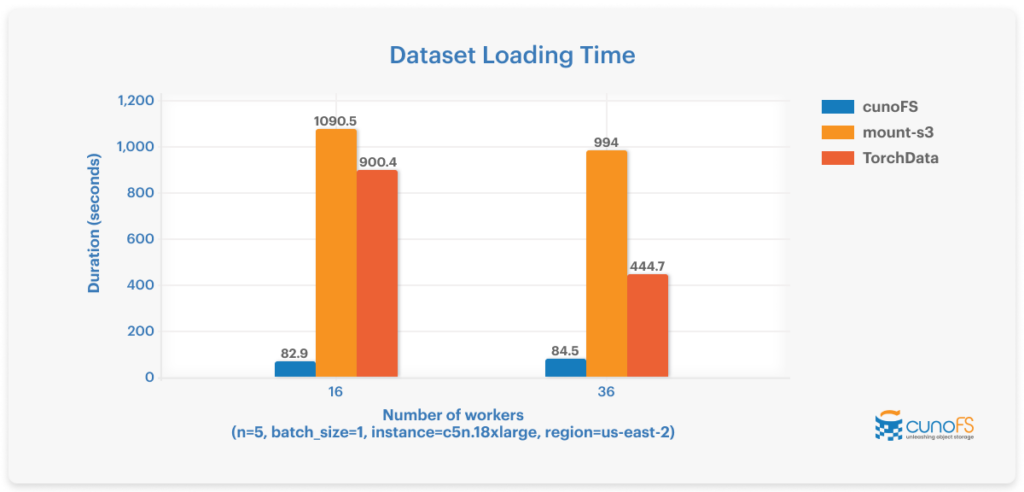
The training split and image data (consisting of 118,287 images totalling 19.3GB) from the COCO 2017 dataset was used to test loading time. As the graph shows, the cunoFS PyTorch optimizations load data much faster than MountPoint for Amazon S3 (mount-s3) and TorchData.
Save (at least) 70% over AWS EFS for ML use cases
High-performance cloud storage like AWS EFS and Google Cloud Filestore becomes increasingly expensive for ML applications as the amount of data you need to train your models grows.
Efforts to reduce these costs come with pitfalls: staging data manually to EBS or EFS and trying to limit volume size restricts the amount of data you can use to train your models, discarding old data that has become expensive to store limits the effectiveness of re-training, and using PyTorch’s built-in ability to load data directly from S3 using its slow API compromises performance.
cunoFS lets you run your unmodified ML applications directly on scalable object storage as if it were a local filesystem, with greater performance, while retaining the cost savings that make object storage attractive. For example, storing 5 TB of training data on Amazon EFS has a monthly cost of around $410 USD, while the same data usage using cunoFS + AWS S3 costs only $115, resulting in a 71% storage cost saving.
How the cunoFS high-performance data loader works with your machine learning system

Here’s how you use it in practice:
- Install and configure cunoFS and connect it to your object storage (such as an S3 bucket).
- Activate your cunoFS environment by running the cuno command, which launches your preferred shell with the cunoFS layer enabled.
- Move your data into S3 via cunoFS. This is as simple as running the cp command and copying your data using either a path or URI. There’s no need to use the S3 API or AWS CLI — everything acts like a native filesystem.
- Set these required environment variables to enable the cunoFS PyTorch data loading optimizations:
-
export CUNO_SPEEDUP_PYTHON=1 export PYTHONPATH="/opt/cuno/lib/${PYTHONPATH+:$PYTHONPATH}" - Install the cunoFS PyTorch accelerator package (available upon request)
Optimize the performance and price efficiency of your PyTorch ML workloads in minutes
ML developers are always looking to squeeze more value out of the investment they’ve made in building their ML systems, collecting and cleaning data, and storing and training their models. cunoFS provides an additional means to optimize these existing systems with little to no additional work. For those designing and developing new ML systems, cunoFS offers significant cost and performance optimizations over the default data loader provided by PyTorch, providing an efficient foundation for new projects right from the start.
Organisations can sign up for a free 14-day evaluation license. For educational institutions and hobbyists, cunoFS provides generous free usage allowances so that everyone can run their machine learning workloads on affordable S3 storage, without having to worry about the performance compromises of other storage approaches.
cunoFS is a versatile solution for running any POSIX application or workload on object storage as if it were a native filesystem, and is not just limited to ML applications. You can check out cunoFS now, for free personal use and evaluation.



